A task-based audit run as a non-technical SMB founder. Finds three structural HITL gaps in how the product handles multi-step agentic work.

Google's Errors Audit framework puts it plainly: "errors and failures are an inevitable part of any product experience." The real question is never whether an agent will fail, but whether the interface is designed to handle it when it does. I ran the same task across multiple autonomous agents before writing a word of this, compared where each one broke down, and used that as the lens for this audit.
I chose a non-technical SMB founder because this is the user who can't recover when the agent fails. Technical users have workarounds. She doesn't.
Julia has a product curation call on Thursday. She opens SAI and types:
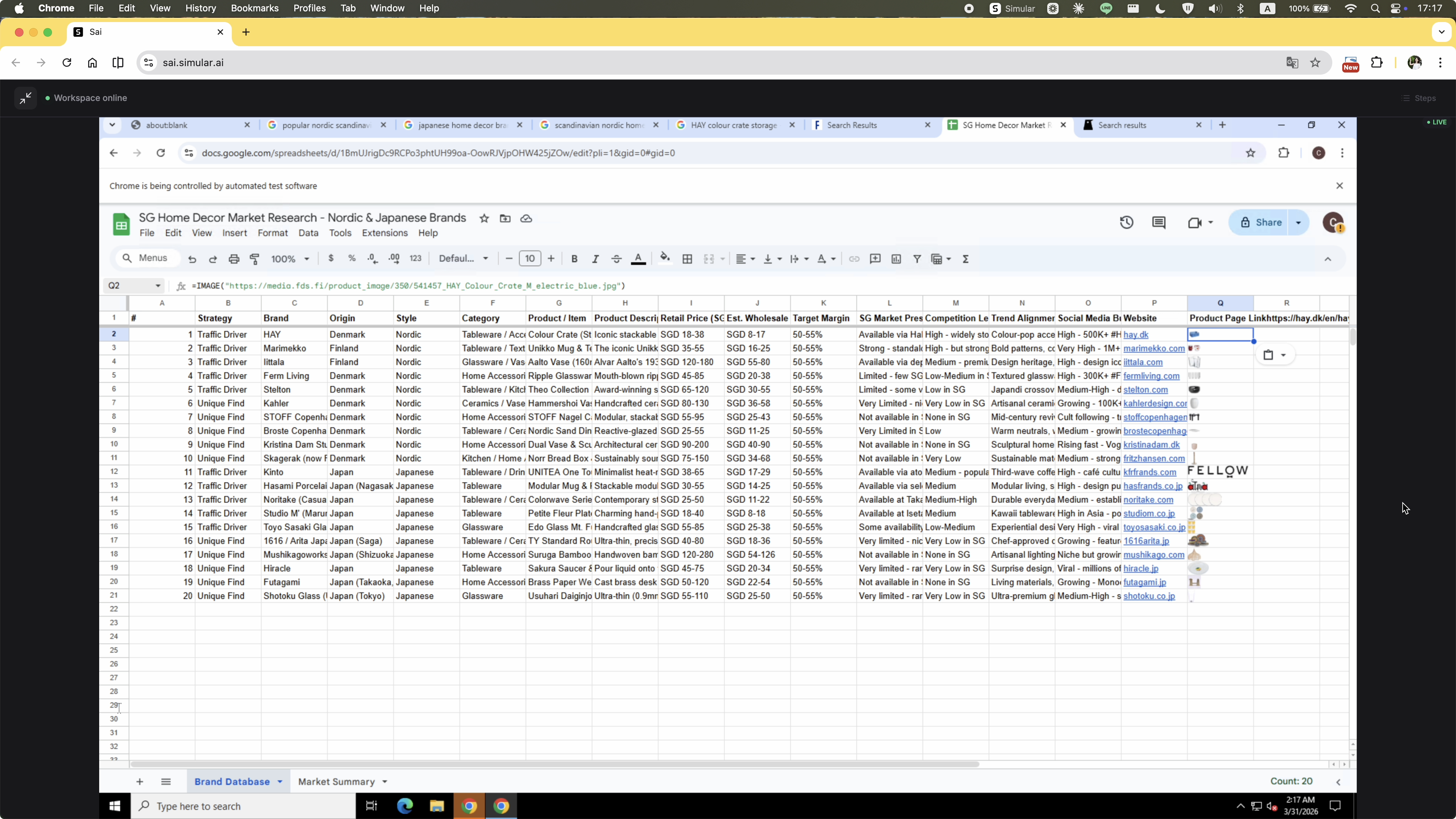
"I am launching a home decor curation brand in Singapore, focusing on Nordic and Japanese home accessories (e.g., vases, small lighting, stools, stationery — no large furniture). Please research brands popular in Singapore and trending in Europe/Japan, curate 20 items with market analysis and pricing, then compile everything and images into a Google Sheet report I can use for import decisions."
This task requires the agent to cross multiple capability boundaries in a single run. That's exactly where HITL design breaks down if it isn't built for it.
The task ran across multiple sessions. These are the key moments — progress, friction, and failure.
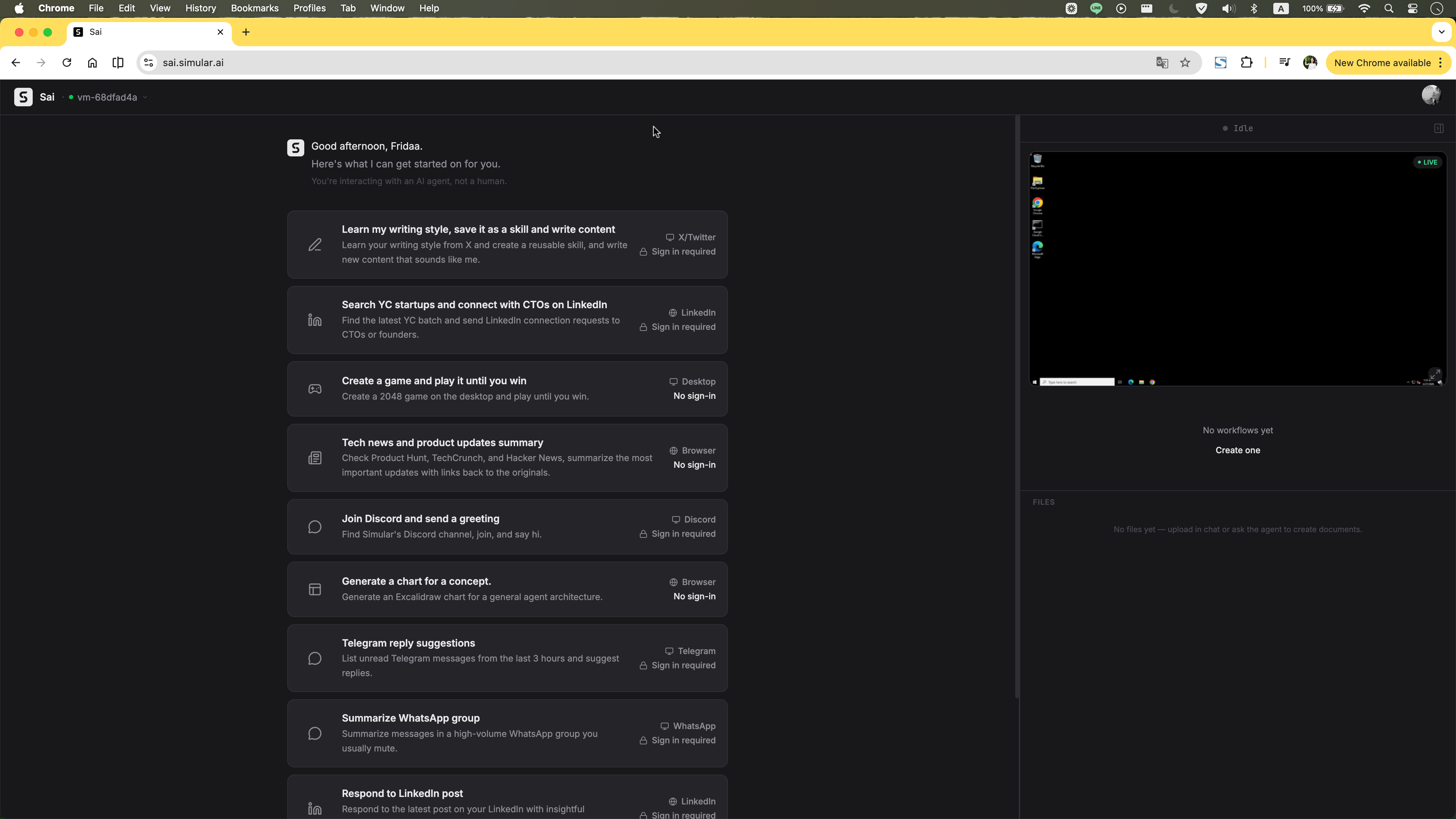
The homepage tries to guide users with example tasks — the right instinct. But presenting too many at once creates cognitive overload rather than clarity. On top of that, the layout immediately exposes a virtual desktop panel on the right. For a first-time user, there's no explanation of what the VM is, why it's there, or what they're supposed to do with it. Two unfamiliar concepts compete for attention before anything has even started.
Clicking into the VM to see what the agent is doing transfers control to the user. The agent pauses. There's no observer mode — any attempt to watch could accidentally take over.
The execution stream updates constantly, but its contents have no hierarchy. Process logs, agent reasoning, and required actions all look identical — a single animated line of text with no way to distinguish what the agent is doing from what it needs. There's no high-level progress summary, no stage indicator, no sense of how far along the task is. The user is left staring at a stream they can't read, repeatedly wondering whether anything is actually happening.
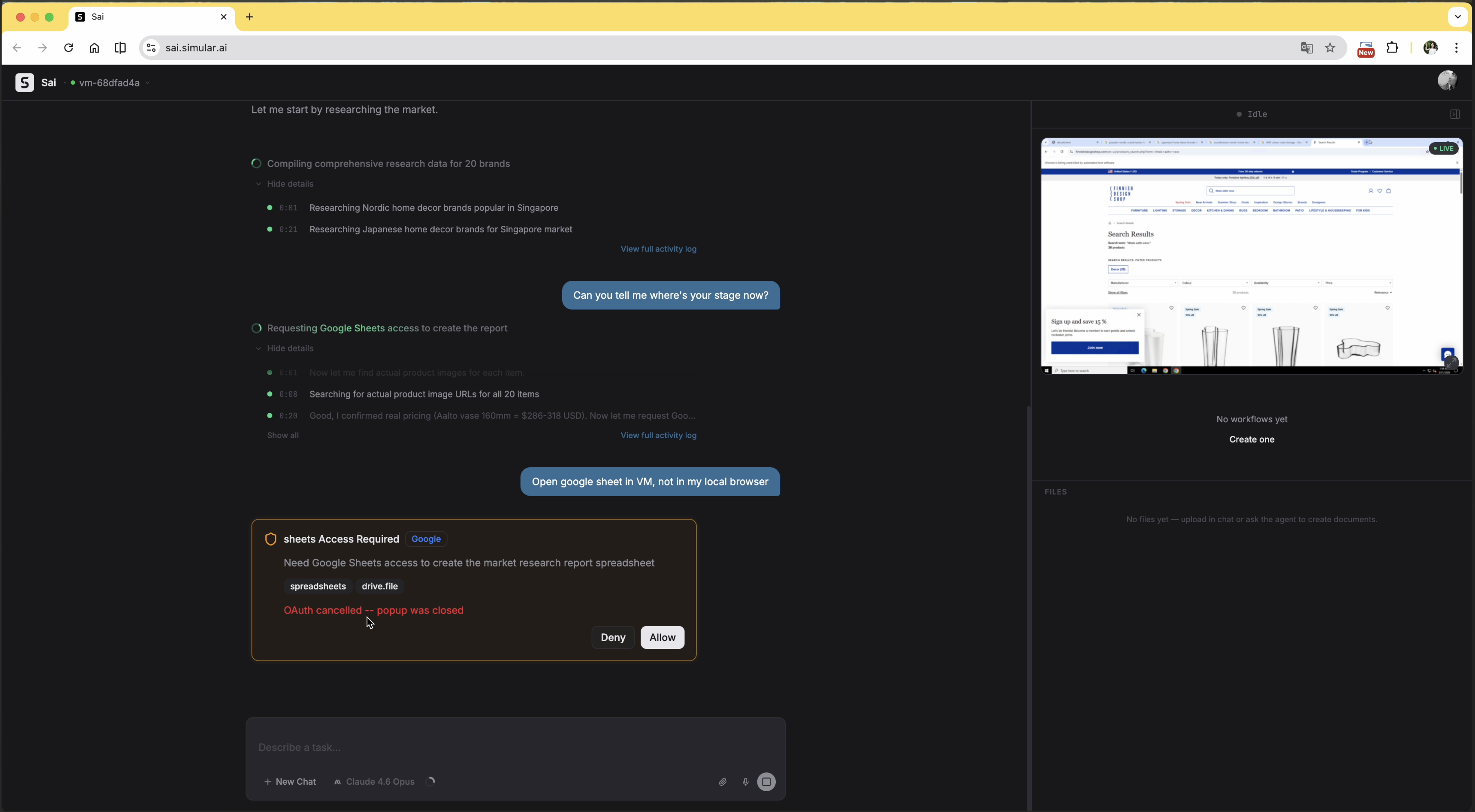
The task was running entirely inside the agent's virtual machine. When Google Sheets access was needed, the auth prompt appeared as a native dialog on the user's local desktop — completely outside the VM. The user assumed the agent would handle everything remotely, so this was unexpected. They denied it.
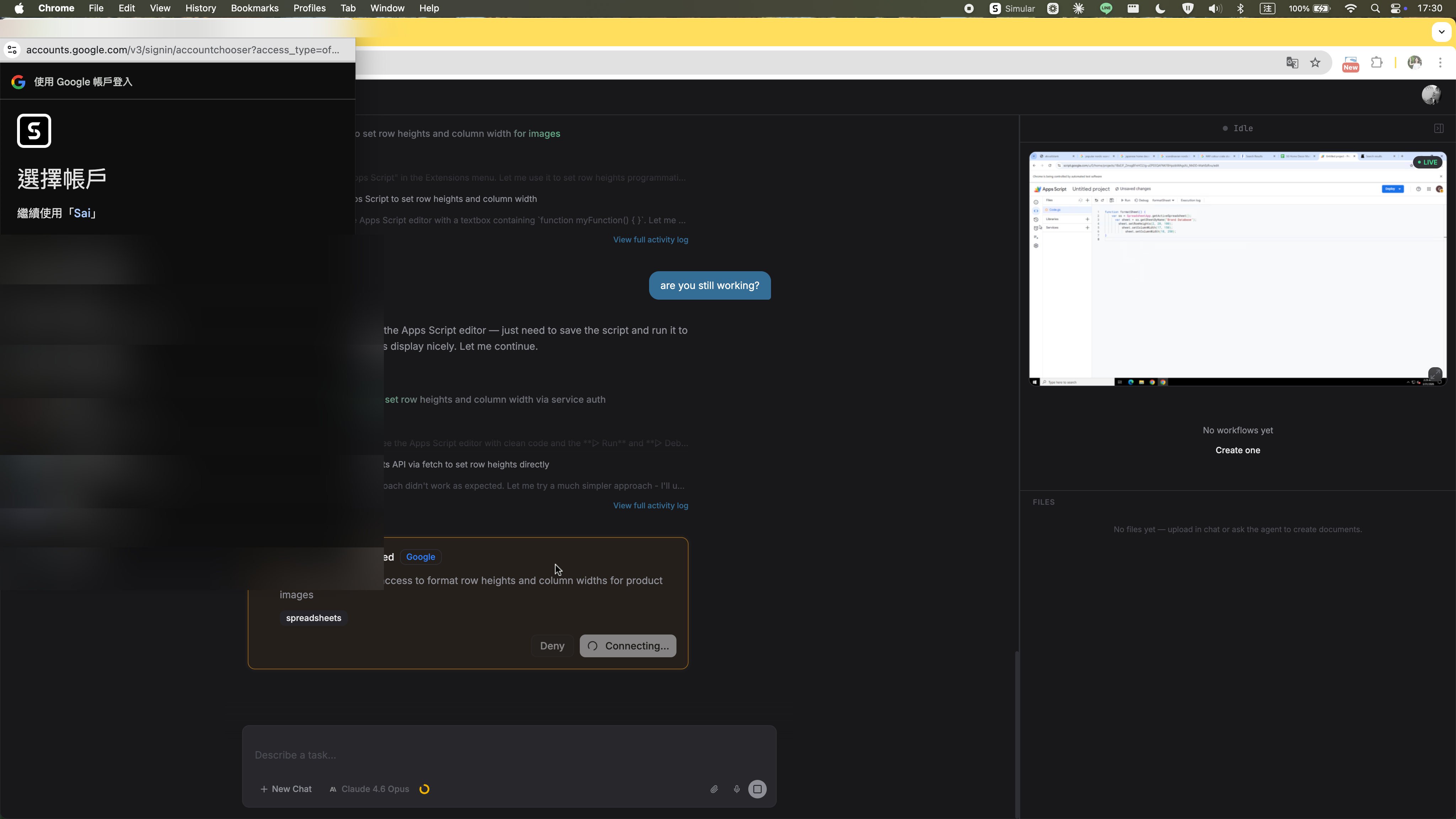
After the denial, the agent didn't pause or ask how to proceed. The auth prompt kept reappearing. The user had to explicitly type into the chat — at least twice — asking to sign in through the VM instead. Only then did the agent accept the instruction and open the auth flow inside the VM.
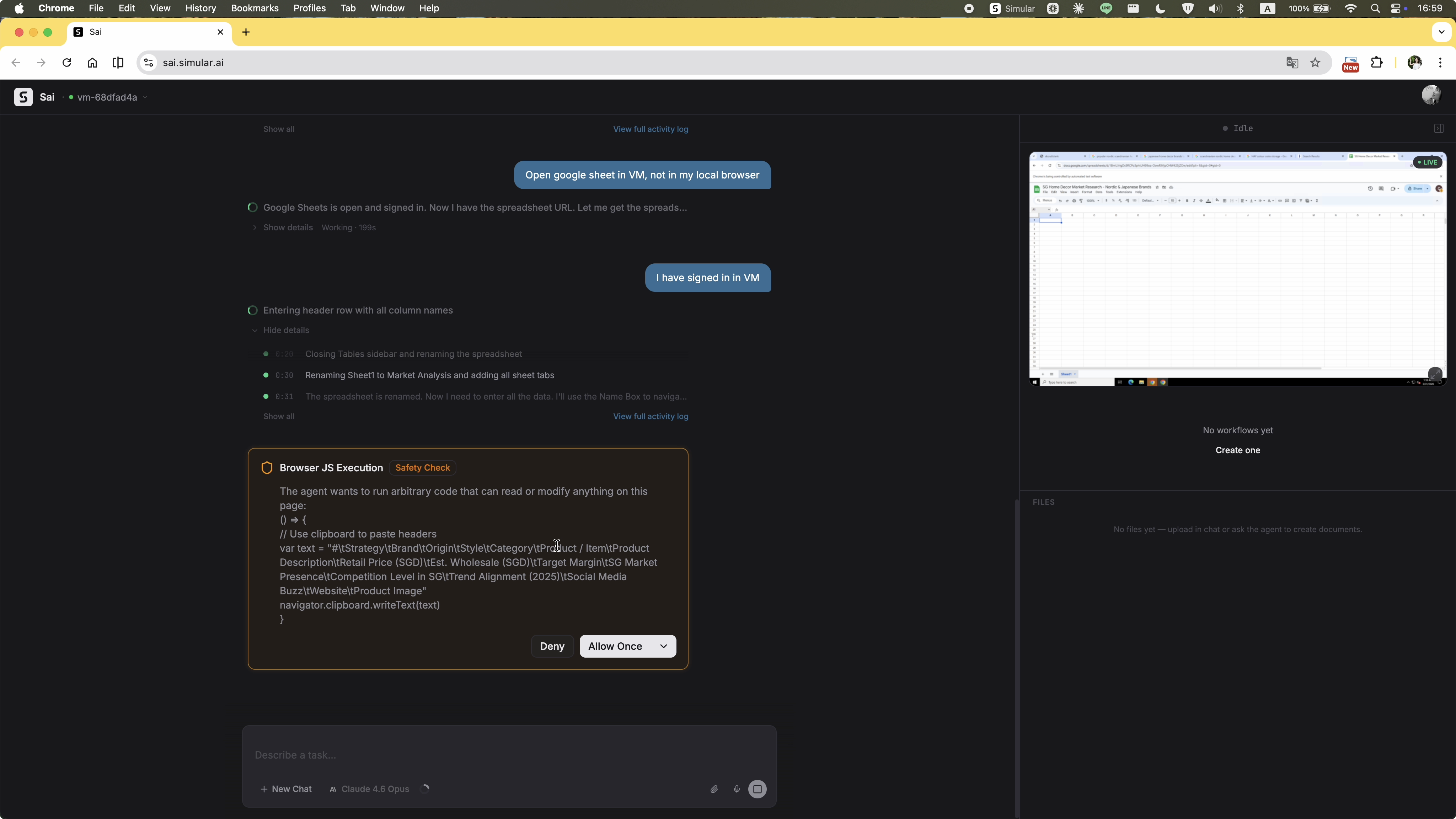
A "Browser JS Execution — Safety Check" dialog appears, showing raw JavaScript code. For a non-technical user, there's no way to evaluate what this code does, why the agent needs it, or whether allowing it is safe. The permission UI is written for developers, not for the person being asked to approve it.
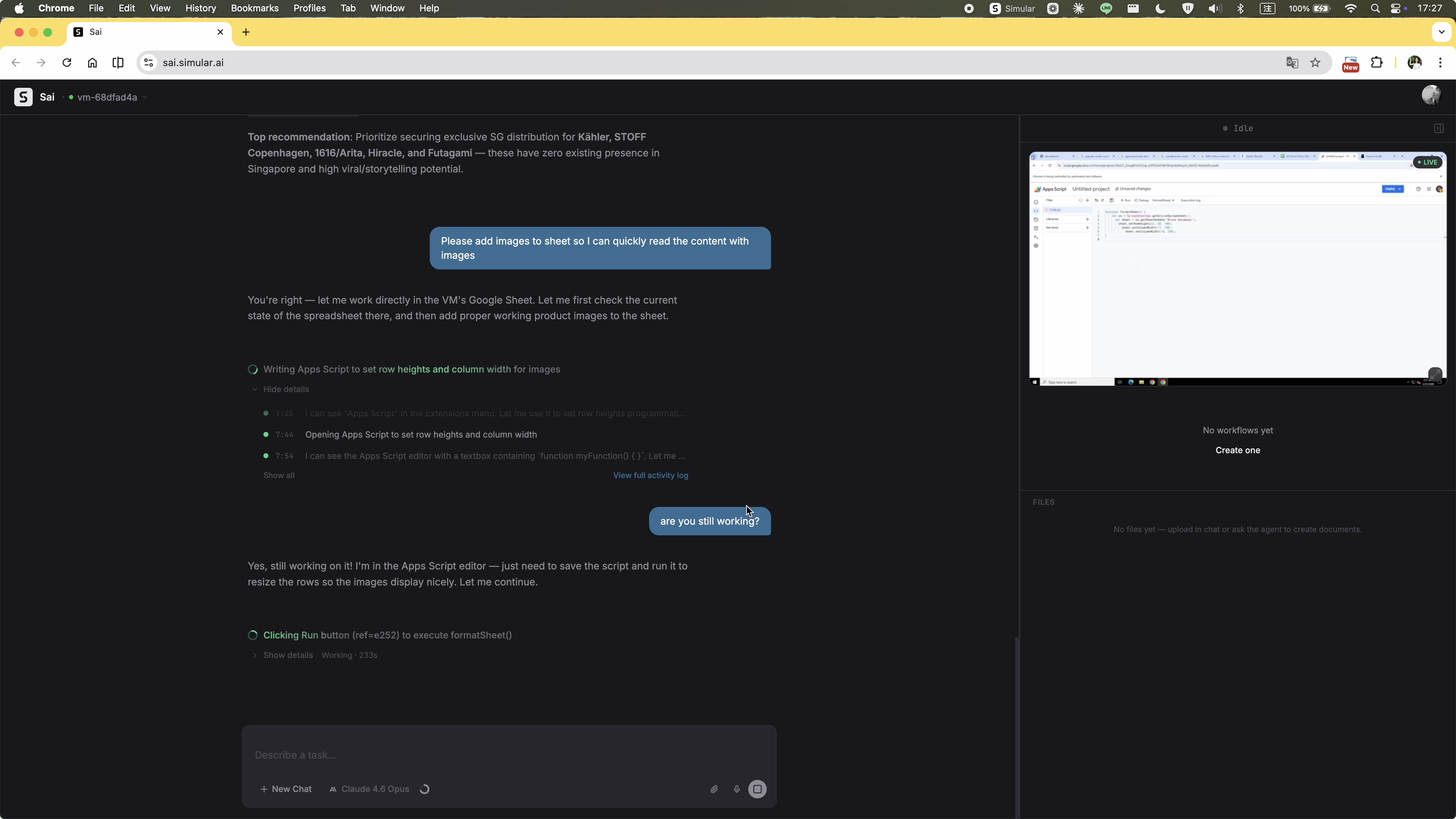
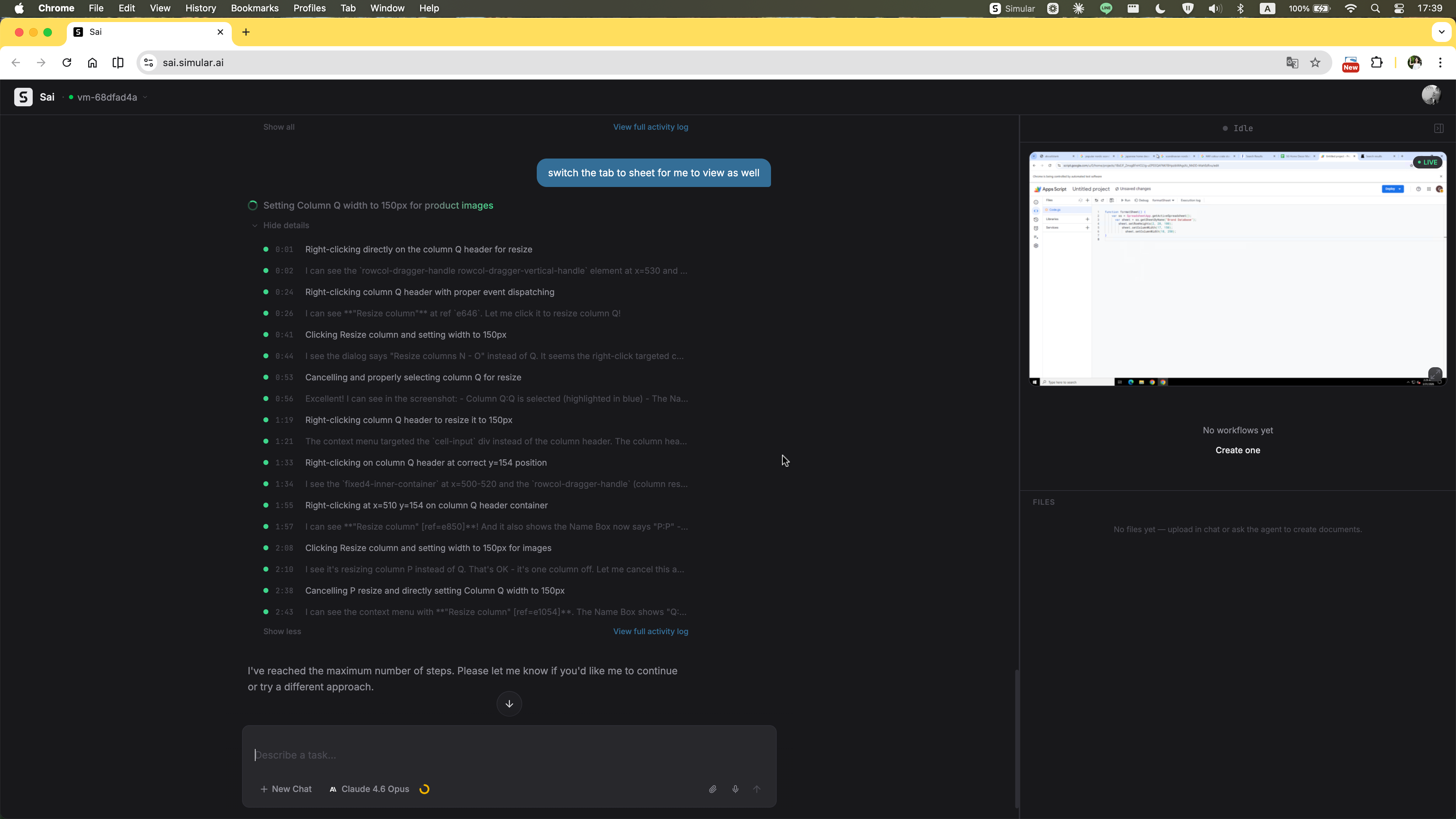
The agent stops mid-task with a single line: "Please let me know if you'd like me to continue or try a different approach." No summary of what was completed, no partial output handed over, no indication of how close it was to finishing. The user is left with nothing actionable — confused about what just happened and with no clear path forward except starting over from scratch.
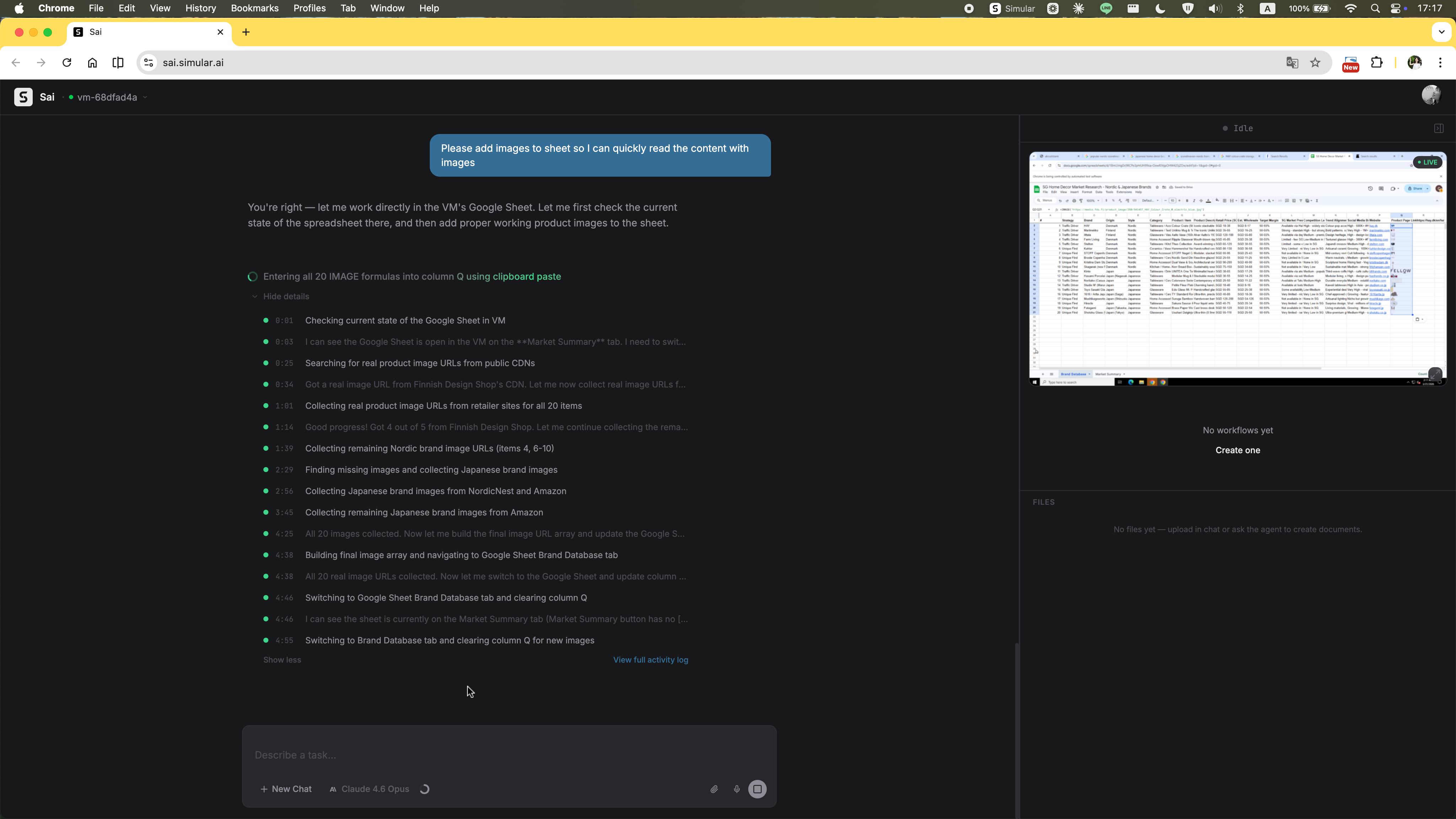
The original prompt explicitly asked for images of the selected items. The agent produced the spreadsheet without them and gave no explanation for the omission. The user had to ask again — restating a requirement that was already there from the start.
The agent's final message is a long block of prose. The Google Sheet URL is somewhere inside it — no card, no clear action, no structured handoff. The user has to scan through the text to find it, then figure out what to do next on their own.
A multi-step research, curation, and remote file creation task — completed. The output is passable: items are listed, pricing is included. The product selection feels a little generic and the analysis isn't quite at the depth you'd act on without review. The capability is real, but it's not yet at the level where you'd trust it to run unsupervised. Which is exactly why the interface needs to be designed for a human who's still very much in the loop.